Já falamos sobre várias formas de utilizar módulos no JavaScript aqui no blog, usando AMD, CommonJS e UMD.
Mas agora o JavaScript tem suporte a módulos nativos! Quer aprender como utlizar? Vem comigo =)
O que são EcmaScript Modules?
EcmaScript é o que podemos chamar de “a documentação da linguagem JavaScript”.
É o lugar onde é definido como as coisas devem funcionar na linguagem.
Você já deve ter lido alguns posts aqui do blog, onde eu falo sobre meus workflows para trabalhar como módulos no JavaScript. Se ainda não leu, pode ler aqui, aqui e aqui.
Se você perceber, não existia uma forma padrão de criar módulos em JS sem passar a informação pelo escopo global.
Usávamos técnicas como IIFE, AMD, CommonJS (Node), UMD… tudo para tentar modularizar nossas aplicações, e não deixar o código virar um espaguete em arquivos com 4k linhas de código.
Então surgiu essa nova especificação para salvar nossas vidas: EcmaScript Modules (ou ES Modules, para os mais chegados).
E a ideia dessa especificação é exatamente o que o seu nome diz: permitir a modularização dos nossos códigos JS, sem precisar passar pelo escopo global :D
Da hora, não!?
Vamos ver como ela funciona? Vem comigo!
Strict
Já vou começar falando que não precisamos mais usar a diretiva 'use strict': ES Modules são strict por padrão!
Como funcionam os ES Modules?
Vamos ver na prática como é o funcionamento dos módulos! Eles ainda não estão implementados totalmente no Node.js, mas na versão mais recente do Chrome você já consegue usá-los!
Obs.: Não testei em outros navegadores, mas aqui você consegue ver o suporte atual dessa feature.
A primeira coisa a fazer é criar um arquivo index.html, onde iremos testar nosso código. Vamos criar uma estrutura básica:
1 |
|
Essa é uma estrutura padrão de uma página em HTML5, com um pequeno detalhe: perceba que a tag script tem um type="module". Isso faz o browser “ativar” a feature de módulo, e todo o código escrito ali dentro dessa tag script é reconhecido como um módulo.
Lembrando que ES Modules são strict por padrão: veja que, ainda que não façamos uso da diretiva 'use strict', o resultado de this será undefined no exemplo acima, e não o objeto global window =)
E como boa prática, para separar o código JS do documento HTML, usamos a mesma ideia de sempre: uma tag script com o atributo src, mas com a adição do type="module":
1 |
|
E só colocamos no arquivo main.js o console.log que estava na index.html:
1 | console.log('this:', this) |
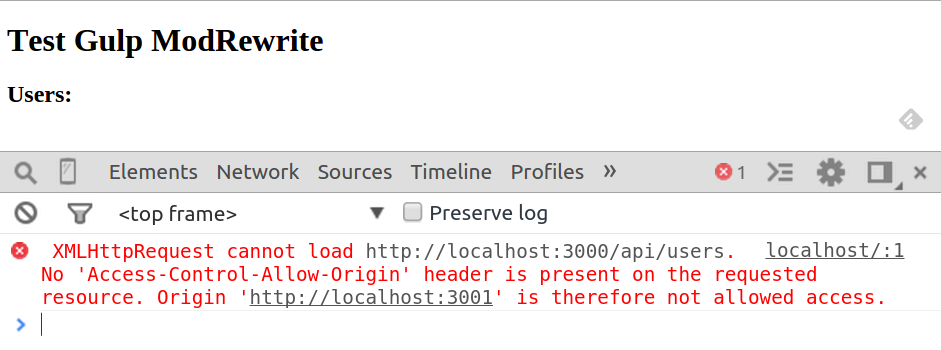
Só tem um pequeno problema: ao tentar abrir esse arquivo apenas clicando duas vezes nele, ele será aberto no navegador usando o protocolo file://. E por se tratar de um módulo, o navegador não permite acessá-lo dentro de uma página web sem ser via o protocolo HTTP, dentro da mesma origem (mesmo domínio), devolvendo no console um erro de CORS:
1 | index.html:1 Access to script at 'file:///media/storage/code/test-es-modules-browser/02/main.js' from origin 'null' has been blocked by CORS policy: The response is invalid. |
Pra resolver isso, é preciso executar o index.html à partir de um servidor HTTP.
Vamos usar o http-server.
E pra facilitar nossa vida, se você tiver a última versão do Node.js instalado na sua máquina, você deve ter também, além do NPM, uma ferramenta chamada npx, que permite usar módulos globais sem instalação. Para usar o http-server à partir do npx, acesse o diretório onde você criou os arquivos index.html e main.js, e execute o comando:
1 | npx http-server -c-1 |
Esse comando vai servir o index.html no endereço http://localhost:8080. Acesse esse endereço no seu navegador, e a mensagem que estava aparecendo no console deve estar sendeo exibida corretamente =)
Detalhe: o -c-1 ao final do comando é apenas para não deixar o http-server fazer cache, e evitar problemas conhecidos haha :D
Agora podemos voltar ao assunto :P
Ok, mas qual a utilidade de ter módulos?
Basicamente duas:
- A possibilidade de quebrar arquivos gigantes em arquivos menores, com responsabilidades melhor definidas;
- Reutilização de código, já que poderemos isolar conforme a necessidade.
Vamos começar com um exemplo simples: uma função de soma. Crie um arquivo chamado sum.js:
1 | function sum (a, b) { |
Agora, para que possamos utilizar esse módulo, ele precisa estar disponível para ser importado, lembrando que módulos têm um escopo próprio, e não são compartilhados no escopo global.
Para fazer isso, temos algumas formas. Vamos aprender e analisar cada uma delas:
Export default: Exportando a referência da função
A maneira mais simples de exportar a função é usando a seguinte expressão no final do arquivo sum.js:
1 | export default sum |
Isso irá exportar a função de forma “default”. Vamos falar sobre o que isso significa em breve.
Agora, para que possamos importar e usar essa função, podemos adicionar, no início do nosso arquivo main.js, a seguinte expressão:
1 | import sum from './sum.js' |
Dessa forma, estamos importando a função que foi exportada como “default” do arquivo sum.js, atribuindo o valor exportado à uma variável nomeada sum.
Podemos usar qualquer nome para importar um valor que foi exportado como “default”:
1 | import arroz from './sum.js' |
Isso faz com que com que a variável arroz seja criada e receba a referência da função sum, que foi exportada do arquivo sum.js :)
Voltando ao exemplo, vamos tentar agora usar a função sum, importada no arquivo main.js. Logo após a chamada de “import” da função sum, adicione o código:
1 | console.log(sum(1, 2)) |
Ao atualizar a página, você verá no console o valor 3 :)
Como você pode perceber, quando usamos export default não precisamos, necessariamente, dar um nome ao valor exportado, pois ele pode ser importado com qualquer nome.
Então temos a opção de exportar diretamente uma função (nomeada ou não) do arquivo sum.js, dessa forma:
1 | export default function sum (a, b) { |
Veja que agora, no arquivo sum.js, apenas tiramos o export default sum do final do arquivo, e exportamos diretamente a função, dessa forma em forma de expressão, como função nomeada, não como uma função literal.
Se podemos usar a função como expressão, o nome dela é opcional. O código abaixo também funciona corretamente:
1 | export default function (a, b) { |
Veja que a expressão da função foi exportada sem um nome =)
Pra reduzir ainda mais esse código, é possível exportar uma arrow function:
1 | export default (a, b) => a + b |
Se você não entende a sintaxe de uma arrow function, eu escrevi sobre o assunto aqui
E isso vale para qualquer tipo de dado (funções, strings, objetos, arrays, promises, etc).
Export nomeado
Podemos também exportar de forma nomeada, forçando assim a obrigatoriedade de um nome específico na hora de importar o módulo.
Vamos alterar o tipo de exportação do módulo sum.js. Primeiro, vamos separar novamente a criação da função, e a linha que faz a exportação:
1 | const sum = (a, b) => a + b |
No código acima, só criamos uma variável sum, e atribuímos a ela a função, e então exportamos essa função.
Para usarmos o export nomeado, nosso código deve ficar assim:
1 | const sum = (a, b) => a + b |
Perceba que simplesmente trocamos a palavra default por chaves, e colocamos o nome que será exportado entre as chaves. Só como adendo: essas chaves não são chaves de criação de um novo objeto, ok? É outra sintaxe =)
Se você executar o código como está, você deve ver o seguinte erro no console:
1 | Uncaught SyntaxError: The requested module './sum.js' does not provide an export named 'default' |
Isso porque não fizemos nenhuma exportação “default” no nosso módulo, temos apenas um export nomeado.
Beleza, mas então como importamos um módulo que foi exportado de forma nomeada?
Bem simples! No arquivo main.js, apenas envolva a palavra sum, que foi usada como variável que recebe o módulo, entre chaves:
1 | import { sum } from './sum.js' |
Veja que o negócio segue um padrão: quando você exporta um módulo com default, você pode dar qualquer nome na hora de importar. Já se exportar de forma nomeada, na hora da importação é sempre necessário usar o mesmo nome que foi usado para exportar.
Podemos ainda exportar a função sum de forma nomeada na mesma linha, apenas fazendo assim no arquivo sum.js:
1 | export const sum = (a, b) => a + b |
O interpretador da linguagem vai entender o nome da variável - ou o nome da função, quando usado uma função nomeada - como o nome a ser exportado. Bem legal né? =)
Agora, vamos ver o que acontece se, na hora de importar o módulo, usarmos um nome diferente do que foi exportado. No arquivo main.js, vamos trocar sum por arroz:
1 | import { arroz } from './sum' |
Obviamente recebemos um erro:
1 | Uncaught SyntaxError: The requested module './sum.js' does not provide an export named 'arroz' |
Mas e se eu quisesse usar mesmo arroz ao invés de sum, é possível?
Sim! E não só é possível renomear um módulo que foi exportado com um nome, como é bem simples, veja só. Ainda no arquivo main.js, vamos fazer nosso módulo funcionar com o nome arroz:
1 | import { sum as arroz } from './sum.js' |
Veja que simples: só precisamos usar a palavra as (como), ou seja: “importe sum como arroz lá do arquivo ./sum.js“ :D
Simples não? =)
Podemos usar a mesma ideia para renomear um export nomeado! Vamos voltar ao arquivo sum.js. Ele estava assim:
1 | export const sum = (a, b) => a + b |
Agora vamos exportar sum com o nome plus:
1 | const sum = (a, b) => a + b |
Lembra que eu falei que as chaves no export não eram de um objeto? Então.. essa é a sintaxe para renomear uma exportação. É como se disséssemos: “Exporte sum como plus“ =)
E agora só temos que fazer a importação correta do nome plus no arquivo main.js para tudo voltar a funcionar:
1 | import { plus } from './sum.js' |
Pronto! =)
Uma coisa interessante de notar: lembra do erro quando nós exportamos a função sum de forma nomeada, mas tentamos importar como default (sem usar as chaves)? O erro foi o seguinte:
1 | Uncaught SyntaxError: The requested module './sum.js' does not provide an export named 'default' |
Veja a dica: o erro diz que o módulo sum.js não proveu um export nomeado como “default”.
Isso significa que podemos fazer algumas mandingas, do tipo:
No arquivo sum.js, exportamos a função como “default”:
1 | const sum = (a, b) => a + b |
E no arquivo main.js, fazemos a mandinga:
1 | import { default as plus } from './sum.js' |
Veja que default pode ser usado como um nome para renomear o módulo! Claro que seria muito mais simples fazer apenas:
1 | import plus from './sum.js' |
Mas o exemplo foi só pra você entender que isso também é possível, e pode ajudar em alguns casos que veremos mais adiante =)
Como você já deve imaginar, podemos fazer também o processo inverso: renomear um módulo para ser exportado como default, dessa forma (no arquivo sum.js):
1 | const sum = (a, b) => a + b |
Exportando mais de um valor por módulo
Para exportar mais de um valor por módulo, vamos criar um novo arquivo chamado calculator.js, e nesse arquivo vamos criar funções para as operações matemáticas mais comuns:
1 | const sum = (a, b) => a + b |
Para exportar facilmente cada uma dessas funções, só precisamos usar a palavra chave export antes de cada declaração:
1 | export const sum = (a, b) => a + b |
Pronto!
Certo, mas como importar várias funções de uma única vez?
Simples: lá no nosso arquivo main.js, vamos importar essas funções de calculator.js:
1 | import { sum, sub, mult, div } from './calculator' |
Show! Ainda tem a segunda forma de exportar lá do calculator.js. Podemos fazer assim também:
1 | const sum = (a, b) => a + b |
Que funciona do mesmo jeito. Escolha o que fica melhor para o seu caso e use :D
Importando vários módulos nomeados de uma só vez
No último exemplo, importamos vários módulos em uma só chamada. Mas é possível também importar todos os módulos que foram exportados de forma nomeada, usando o operador especial *, olha só (no main.js):
1 | import * as calculator from './calculator.js' |
Dessa forma nós importamos todos os valores que foram exportados com um nome em calculator.js, e atribuímos esses valores como propriedades de um objeto que chamamos de calculator.
E se tivéssemos algum valor exportado de forma default no calculator.js?
Vamos ver como ficaria esse caso. Agora o arquivo calculator.js deve ficar assim:
1 | const sum = (a, b) => a + b |
Veja que criamos uma variável obj e exportamos essa variável com o default. Para ter acesso a esse objeto no main.js, onde foi usado o * para importar todos os módulos, podemos usar calculator.default, já que esse objeto foi exportado como default:
1 | console.log(calculator.default) // {} |
Lembre-se que o export default pode ser exportado de duas formas:
1 | export default obj |
Ou ainda, usando a forma nomeada:
1 | export { obj as default } |
Por isso conseguimos pegar esse valor quando importado usando o * :)
Nesse último exemplo do arquivo calculator.js, é importante frisar que só podemos ter um único módulo exportado como default, por motivos óbvios =)
Mas se não estiver tão claro, é só pensar no seguinte: o nome default pode ser usado como um “nome” na hora de importar. Se você tiver dois export default, qual deles deveria ser usado com o nome default, na hora de importar?
Deu pra entender a ideia? Sempre que você precisar exportar um só valor, pode usar tanto o default como o formato nomeado. Mas se for exportar mais de um valor, use o formato nomeado.
O default não é obrigatório, e muitas vezes desencorajado por algumas pessoas da comunidade, com a alegação de que exports nomeados podem ser melhor “padronizados” já que eles precisam ter o nome exato na hora de importar.
Exemplo: você vai importar o jQuery na sua aplicação. Se ele fosse exportado de forma default, você poderia usar em um arquivo:
1 | import jQuery from './jquery.min.js' |
Em outro arquivo, poderia usar:
1 | import jQ from './jquery.min.js' |
E assim por diante. Agora, se o export for nomeado, você é forçado a usar o nome que foi usado para exportar - tudo bem que dá pra renomear, mas ainda assim fica muito mais explícito =)
Acho que deu pra entender :)
Importar o default separado dos nomeados
Também é possível fazer o import do valor default de forma separada dos nomeados, mas ainda na mesma chamada, veja o que vamos fazer no arquivo main.js:
1 | import calc, { sum, sub, mult, div } from './calculator.js' |
Veja que calc fica fora dos parênteses, pois é o nome dado ao valor que foi exportado com default :)
Exportar importando
Ainda tem uma outra feature interessante, onde você pode exportar um módulo, fazendo a importação desse na mesma sentença. Vamos fazer o seguinte: vamos criar um arquivo para cada operação matemática: sum.js, sub.js, mult.js e div.js.
Ao fazer isso, vamos mover cada função que está em calculator.js para o seu respectivo arquivo, e exportar de forma default em cada um.
Depois, só precisamos importar tudo no arquivo calculator.js, e então exportar. Mas podemos fazer ainda melhor, saca só:
1 | export { default as sum } from './sum.js' |
Veja que usamos a sintaxe export from, que, basicamente, importa o módulo que foi exportado como default do seu arquivo setado após o from, nomeia esse módulo e faz o export dele à partir do arquivo calculator.js.
Assim, podemos fazer a importação nomeada de qualquer um desses módulos direto do calculator.js no main.js:
1 | import { sum, sub, mult, div } from './calculator.js' |
Da hora não? Isso é bem legal pra quando precisamos separar os nossos módulos, mas ainda assim queremos uma melhor organização, fazendo o import à partir de um único módulo central =)
É importante dizer também que esse sistema de módulos é estático. Significa que não podemos, por exemplo, importar arquivos à partir de um nome dinâmico.
Vou exemplificar: imagine que você tem os seguintes arquivos: mod1.js, mod2.js, mod3.js.
Você poderia pensar: eu tenho um padrão no nome dos meus arquivos. Talvez eu possa fazer um loop e importá-los todos de uma só vez, não?
NÃO!
Não dá pra fazer algo assim, por exemplo:
1 | const arrayDe1A3 = Array.from({ length: 3 }, (_, i) => i + 1) |
Uma porque eu acabei de falar que o import é estático :P
Outra que item seria o nome da variável atribuída para cada import.
E essa sintaxe não aceita nomes dinâmicos, como usado em ./mod${item}.js. Ainda que usasse concatenação - algo assim: import mod1 from 'mod' + item - não funciona.
Depois do from, você só consegue usar aspas simples ou duplas, não dá pra usar template literals (as crases).
Por isso é importante que os seus import estejam sempre no início do seu arquivo. Nunca faça algo do tipo:
1 | import sum from './sum' |
Apesar de funcionar, sempre faça todos os imports no início do arquivo, e só depois de todos os imports é que você pode usar os valores, ok? =)
Módulos dinâmicos
A sintaxe que eu acabei de apresentar é estática, mas com certeza tem alguns momentos em que precisamos importar um ou outro módulo sob demanda, e de forma dinâmica, afinal, precisamos de liberdade e performance =)
Para isso, existe uma especificação que está para entrar também nos ES Modules, para conseguirmos importar módulos de forma dinâmica: é a função import().
Isso mesmo, uma função! Quando usamos import() como função, passando via parâmetro o caminho do módulo que queremos importar, ela nos retornará uma Promise.
E dessa vez, o nome do módulo pode ser passado de forma dinâmica, sem problemas. E esse import você pode usar onde quiser, inclusive de forma condicional (dentro de um if, por exemplo). :D
Vamos ver alguns exemplos.
Começaremos importando no main.js o sum.js:
1 | import('./sum.js').then((sum) => { |
Lembre-se que o import() função sempre retorna uma Promise. Por isso precisamos usar o .then para saber quando essa Promise resolveu com o valor do nosso módulo.
Outro ponto interessante a levar em consideração: após resolver o módulo, sempre será retornado um objeto com todos os valores de forma nomeada. Como lá no módulo sum.js nós exportamos com default a função, aqui nós tivemos que usar sum.default para ter acesso à essa função =)
Como eu tinha dito anteriormente, com o import() função é possível usar nomes dinâmicos. Vamos fazer um teste no main.js:
1 | const module = 'sum' |
Veja que passamos o nome do módulo em uma variável module, e concatenamos com o ./ no início e o .js no final da chamada do nome do arquivo =)
Acho que com isso já dá pra se divertir bastante :D
Considerações finais
Em algumas aplicações atuais, nós vemos import sem o .js no final, e até import de outros tipos de arquivos diferentes de .js, ou ainda a importação de módulos sem passar o ./ na frente, pra representar o caminho do arquivo.
É importante entender que os ES Modules servem apenas para arquivos JS, e não funcionam para importar imagens, markdown, svg, CSS, ou qualquer outro tipo de arquivo.
O que acontece nas aplicações usando libs e frameworks como React, Vue, Angular, etc., é que existe uma ferramenta por trás interceptando esses imports, e transformando esse código antes de ele, de fato, chegar no interpretador do navegador.
Por causa dessas configurações nessas ferramentas - como webpack, parcel, etc - é que conseguimos importar outros tipos de arquivos, mas isso não é o padrão dos ES Modules, ok? É importante estar ciente disso =)
Bom, o artigo ficou bastante extenso, mas acho que eu consegui cobrir, se não tudo, ao menos as partes mais importantes quando se trata de módulos nativos no JS.
Gostou do artigo? Esqueci de algo? Me deixe saber nos comentários, e compartilhe esse post para que mais pessoas aprendam a usar essa feature maravilhosa da nossa amada liguagem <3
Até o próximo artigo :D
]]>